
Generación de datos
The World Wide Web contains about 170 terabytes of information on its surface; in volume this is seventeen times the size of the Library of Congress print collections.
Instant messaging generates five billion messages a day (750GB), or 274 Terabytes a year.
Email generates about 400,000 terabytes of new information each year worldwide.
Fuente: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/
Código Barra
RFID: Radio Frequency Identification
Código QR

Costos para guardar datos
Costos de un disco duro (US-$) / Capacidad (MB)
Fuente: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/

Disponibilidad de datos
Capacidad de nuevos discos duros (PB)
Fuente: http://www.sims.berkeley.edu/research/projects/how-much-info-2003/

Disponibilidad de datos

Disponibilidad de datos

14
Business Intelligence – Definición
Business Intelligence
The term Business Intelligence (BI) represents the tools and systems that play a
key role in the strategic planning process of the corporation. These systems allow
a company to gather, store, access and analyze corporate data to aid in
decision-making.
Generally these systems will illustrate business intelligence in the
areas of customer profiling, customer support, market research, market segmentation,
product profitability, statistical analysis, and inventory and distribution analysis
to name a few.
http://www.webopedia.com/TERM/B/Business_Intelligence.html

Data Warehouse – Definición
15
Data Warehouse:
Abbreviated DW, a collection of data designed to support management decision making.
Data warehouses contain a wide variety of data that present a coherent picture of
business conditions at a single point in time.
Development of a data warehouse includes development of systems to extract data
from operating systems plus installation of a warehouse database systems that provides
managers flexible access to the data.
The term data warehousing generally refers to the combination of many different databases across an entire enterprise. Contrast with data mart.
Fuente:
http://www.webopedia.com/TERM/D/data_warehouse.html

Arquitectura de un Data Warehouse
16
(Gp:) Información
detallada
(Gp:) Resumen
(Gp:) Meta Datos
(Gp:) Datos
(Gp:) Información
(Gp:) Decisión
(Gp:) Fuente: Anahory, Murray (1997): Data Warehousing in the Real World.
(Gp:) Datos
operacionales
(Gp:) Datos
externos
(Gp:) Herramientas
de Data Mining
(Gp:) Herramientas
de OLAP

17
Diferencias entre Bases de Datos y Data Warehouses
Características Bases de Datos Data Warehouses Volumen alto bajo o medio Tiempo de muy rápido normal respuestaFrecuencia de alta, baja actualizaciones permanentemente Nivel de los datos en detalle agregado

OLAP – Online Analytical Processing
18
Ubicación
Producto
Tiempo

Navegación en un cubo OLAP
19
Ubicación
Producto
Tiempo
P1
U1
Drill down:
profundizar una
dimensión

Motivaciones para Almacenar Datos
20
Razones iniciales:
En telecomunicación:
Facturación de llamadas
Potenciales:
En telecomunicación:
Detección de fraude
En supermercados:
Gestión del inventario
En bancos:
Manejo de cuentas
En supermercados:
Asociación de ventas
En bancos:
Segmentación de clientes

Idea básica y potenciales de data mining
(Gp:) Empresas y Organizaciones tienen gran cantidad de datos almacenados.
Los datos disponibles contienen información importante.
(Gp:) La información está escondida en los datos.
(Gp:) Data mining puede encontrar información nueva y potencialmente útil en los datos

Proceso de KDD Knowledge Discovery in Databases
(Gp:) Transformación
(Gp:) Datos
(Gp:) Datos se-leccionados
(Gp:) Preprocesamiento
(Gp:) Datos pre-procesados
(Gp:) Datos transformados
(Gp:) Data Mining
(Gp:) Patrones
(Gp:) Interpretación yEvaluación
(Gp:) Selección
“KDD es el proceso no-trivial de identificar patrones previamente desconocidos, válidos, nuevos, potencialmente útiles y comprensibles dentro de los datos“

SEMMA (SAS Institute)
S: Sample (Training, Validation, Test)
E: Explore (get an idea of the data at hand)
M: Modify (select, transform)
M: Model (create data mining model)
A: Assess (validate model)
23

CRISP-DM
24
http://www.crisp-dm.org/index.htm

Potenciales de Data Mining – 1

Potenciales de Data Mining – 2

Nivel Significado Ejemplo Operación
permitida
Escala nominal “Nombre” de objetos número de telef. comparación
Escala ordinal “Orden” de objetos Notas (1, …, 7) Transformación
(sin distancia) monótona
Escala de Punto cero y unidad Temp. en grados f(x)=ax + b
intervalo arbitrario Cel. (a>0)
Escala de Dado el punto cero Peso en kg f(x)=ax
proporción Unidad arbitraria Ingreso en $
Escala Dado el punto cero Contar objetos f(x)=x
absoluta y la unidad número de autos
Nivel de datos

28
Clasificación de técnicas para la selección de atributos
Filter
Wrapper
Embedded methods

29
Filter
Correlación entre atributos y variable dependiente
Relación entre atributo y variable dependiente
Test chi-cuadrado para atributos categóricos
ANOVA (Analysis of Variance), test KS para atributos numéricos

30
Test Chi-cuadrado
Goodness of Fit
Independence of two variables
Hypotheses concerning proportions

31
Test Chi-cuadrado: Independencia de dos variables
Tenemos 2 variables categóricas
Hipótesis: estas variables son independiente
Independencia significa: Conocimiento de una de las dos variables no afecta la probabilidad de tomar ciertos valores de la otra variable

32
Test Chi-cuadrado: Tabla de contingencia
Tabla de contingencia: matriz con r filas y k columnas, donde
r=número de valores de variable 1
k=número de valores de variable 2

33
Test Chi-cuadrado: Tabla de contingencia
Ejemplo:
Variable 1=Edad, variable 2=sexo
Grado de libertad (degree of freedom):
df=(r-1)(k-1)
Idea:
Comparar frecuencia
esperada con
frecuencia observada
Hipótesis nula:
variables son independientes
r=2
k=2
34
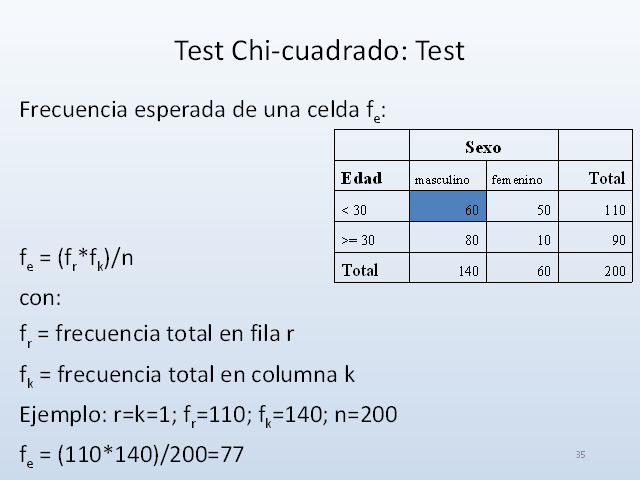
Test Chi-cuadrado: Test
Frecuencia esperada de una celda fe:
fe = (fr*fk)/n
con:
fr = frecuencia total en fila r
fk = frecuencia total en columna k
Ejemplo: r=k=1; fr=110; fk=140; n=200
fe = (110*140)/200=77

35
Test Chi-cuadrado: Frecuencia esperada
Frecuencia esperada vs. observada para todas las celdas:

36
Test Chi-cuadrado
H0: Edad y sexo son independiente
H1: Edad y sexo son dependiente (hay una relación entre edad y sexo)
df = 1 = (r-1)*(k-1)
Valor crítico de chi-cuadrado (df=1, a=0,01)=6,63 (ver tabla)
Chi-cuadrado =
=27,8 > 6,63 => hay que rechazar H0=>edad y sexo son dependiente

37
Test KS

38
Limpieza de datos
Tipos de Datos perdidos (Taxonomía Clásica) [Little and Rubin, 1987]:
Missing Completely at Random (MCAR):
Los valores perdidos no se relacionan con las variables en la base de datos
Missing at Random (MAR):
Los valores perdidos se relacionan con los valores de las otras variables dentro de la base de datos.
Not Missing at Random or Nonignorable (NMAR):
Los valores perdidos dependen del valor de la variable.

39
Transformación de Atributos
F22, monto demanda
502 demandas, Valparaíso
F22, ln(monto demanda +1)
502 demandas , Valparaíso

40
Recency = tiempo entre hoy y última compra
Frequency = frecuencia de compras
Monetary value = monto total de las compras
(Gp:) R
(Gp:) F
(Gp:) M
(Gp:) hoy
(Gp:) Historial de compras
Transformación de Atributos

41
Métodos de Data Mining
Estadística
Agrupamiento (Clustering)
Análisis Discriminante
Redes Neuronales
Árboles de Decisión
Reglas de Asociación
Bayesian (Belief) Networks
Support Vector Machines (SVM)

42
Base de lógica difusa
3
0
3
6
4
2
Edad
1
m
(
A
)
Función de pertenencia
Variable lingüística
“Cliente joven”

43
Agrupamiento con lógica difusa
(Gp:)
(Gp:) C
(Gp:) l
(Gp:) u
(Gp:) s
(Gp:) t
(Gp:) e
(Gp:) r
(Gp:)
(Gp:) C
(Gp:) e
(Gp:) n
(Gp:) t
(Gp:) r
(Gp:) e
(Gp:) s
(Gp:)
(Gp:) =
(Gp:) ^
(Gp:) 1
(Gp:) 1
(Gp:) 1
(Gp:) 1
(Gp:) 1
(Gp:) 1
(Gp:) 1
(Gp:) 1
(Gp:) 0
(Gp:) 0
(Gp:) 0
(Gp:) 0
(Gp:) 0
(Gp:) 0
(Gp:) 0
(Gp:) Grupos estrictos
(Gp:) Grupo difuso 2
(Gp:) Grupo difuso 1

44
Agrupamiento con Lógica Difusa
Algoritmo: Fuzzy c-means (FCM)
n objetos, c clases
ui,j = grado de pertenencia de objeto i a clase j
(i=1, …, n; j=1, …, c)
U = (ui,j)i,j ui,j ?[0,1?; ?ui,j = 1; i = 1, …, n
Función objetivo: min ?? (ui,j)m d2(xi, cj)
xi : objeto i; cj : centro de clase j;
d2(xi, cj): distancia entre xi y cj
m : parámetro difuso (1< m< ?)

45
1. Determina una matriz U con ui,j ?[0,1?; =1
2. Determina los centros de las clases:
cj =
3. Actualiza los grados de pertenencia:
ui,j = Uk = matriz en iteración k
4. Criterio para detener: ??Uk+1 – Uk?? < ?
Algoritmo: Fuzzy c-means (FCM)

46
Segmentación de Clientes
(Gp:) Banco
(Gp:) Producto 1
(Gp:) Producto n
(Gp:) Clientes
(Gp:) Requerimientos
(Gp:) Requerimientos
(Gp:) ¿Qué producto para qué cliente?
(Gp:) ?
(Gp:) ?
(Gp:) ?
(Gp:) ?
(Gp:) ?

47
Segmentación de Clientes
Selección
de atributos
Segmen-
tación
de clientes
Agrupamiento
Clasificación

48
Segmentación de Clientes usando Agrupamiento Difuso
Modelo Objetos: clientes; Atributos: ingreso, edad, propiedades, … Método Fuzzy c-means con c=2, …, 10 clases

Centros de 6 Clases
49

Redes Neuronales
50
(Gp:) å
(Gp:) Conexiones con pesos
(Gp:) Neurona
(Gp:) artificial
(Gp:) natural

51
Neuronas Artificiales
Neuronas “Verdaderas”
Neuronas Artificiales
(Gp:) Núcleo
(Gp:) Cuerpo Celular
(Gp:) Axon
(Gp:) Dendritas
(Gp:) sinapsis
?
w1
w2
…
x1(t)
x2(t)
xn(t)
wn
a(t)
y=f(a)
y
a
w0
o(t+1)

52
Perceptron (1962)
Generalización y formalización de las redes neuronales.
(Gp:) …
(Gp:) x1
(Gp:) x2
(Gp:) x3
(Gp:) xn
(Gp:) …
(Gp:) …
(Gp:) o1
(Gp:) o2
(Gp:) op

53
Perceptron la falla
La función XOR (exclusive or):
x1
x2
y
0
0
0
0
1
1
1
0
1
1
1
0
0
0
1
1
x2
x1
Minsky, Papert (1969)

54
Multilayer Perceptron (MLP)
El 90% de las aplicaciones de redes neuronales están referidas a MLP
¿Cómo resuelvo esto?,? Backpropagation, Un ejemplo:
Es una función no lineal, de una combinación lineal de funciones nolineales de funciones de combinaciones lineales de los datos de entrada; => Clasificación y Regresión no lineal!!

55
Backpropagation un ejemplo
r=3
n=2
s=1
w11
w21
w12
w13
w22
w23
w’11
w’12
xp
op
yp

56
Multilayer Perceptron
Aplicaciones:
Clasificación
Regresión
Redes Neuronales
(Gp:) å
(Gp:) Capa de entrada
(Gp:) Capa escondida
(Gp:) Capa de salida
(Gp:) Conexiones con pesos

57
Inducción de un árbol de decisión a partir de ejemplos
(Gp:) C1, …, C6
(Gp:) C2, C4, C6
(Gp:) C1
(Gp:) C3, C5
(Gp:) Fuga = sí
(Gp:) Fuga = no
(Gp:) E=a
(Gp:) E=m
(Gp:) E=b
Reglas a partir del árbol:
Si E = a y R = a
Fuga = sí
Si E = a y R = b
Fuga = no
…
(Gp:) C2
(Gp:) Fuga = sí
(Gp:) Fuga = sí
(Gp:) Fuga = no
(Gp:) C4
(Gp:) C6
(Gp:) R=a
(Gp:) R=b

58
Inducción de un árbol de decisión a partir de ejemplos
Algoritmos: ID3, C4.5 (Quinlan); CART (Breiman et al.)
Construcción del árbol:
criterio de detención, criterio para seleccionar atributo discriminante
Idea básica de ID3: (ejemplos tienen 2 clases: positivo, negativo)
Criterio de detención: Detiene la construcción del árbol si cada
hoja del árbol tiene solamente ejemplos de una clase (pos. o neg.)
E2(K) = – p+ * log2p+ – p- * log2p- (Entropía de un nodo)
K: Nodo considerado
p+ / p- frecuencia relativa de ejemplos positivos/negativos en nodo K
p+ + p- = 1; 0*log20 := 0
E2(K) ? 0 E2(K) = 0 ? p+ = 0 o p- = 0.
Entropía de K es máximo ? p+ = p-

59
Inducción de un árbol de decisión a partir de ejemplos
Para cada atributo calcula:
MI := (Medida de Información)
m: Número de valores del atributo considerado
pi: Probabilidad que ejemplo tiene el valor i del atributo considerado
(frecuencia relativa del valor i en el nodo considerado)
Ki: nodo i sucediendo al nodo K (i=1, …, m)
E2(Ki): Entropía del nodo Ki (i=1, …, m)
Criterio para seleccionar un atributo discriminante:
Selecciona el atributo con mínimo valor MI !

Regresión Logística (1/2)
Yi = Número de “éxitos” de un experimento con ni repeticiones (ni conocido)
donde la probabilidad de éxito es pi (pi no conocido).
Yi ~ B(ni, pi), i = 1, …, N : Distribución Binominal
Supuesto: pi depende del vector de atributos (Xi) del objeto i.

Regresión Logística
Método de clasificación (m clases)
p = probabilidad de pertenecer a la clase 1 (m=2)
p = ß0 + ß1*x1 + ß2*x2 + … + ßn*xn (no necesariamente en [0,1])
p = (siempre en [0,1])
Odds = p / (1-p) ? p = Odds / (1+Odds)
Odds =
Log(Odds) = ß0 + ß1*x1 + ß2*x2 + … + ßn*xn (= logit)
Estimar ßi con maximum likelihood.

Support Vector Machines Ejemplo Introductorio
Caso Retención de Clientes: “detección de fuga”.
Dada ciertas características del cliente (edad, ingreso, crédito, saldo promedio, comportamiento en general) (atributos)
Determinar si el cliente cerrará su cuenta corriente en los próximos meses.
Aprender de información de otros clientes, generar alguna
“Regla” y aplicar esta regla a casos nuevos.

Teoría de Aprendizaje Estadístico
Minimización del riesgo empírico
Queremos encontrar una función f que minimice:
Donde y es el valor conocido del objeto x, f(x) es la función de inducción y n es el número de objetos

Motivación
Caso particular de dos conjuntos linealmente disjuntos en R2
Antigüedad
Saldo promedio
: No cierra
: Cierra

Motivación SVM
Caso particular de dos conjuntos linealmente disjuntos en R2
Antigüedad
Saldo promedio
: No cierra
: Cierra
W

Support Vector Machines(Para Clasificación)
IDEA:
Construir una función clasificadora que:
Minimice el error en la separación de los objetos dados (del conjunto de entrenamiento)
Maximice el margen de separación (mejora la generalización del clasificador en conjunto de test)
Dos objetivos:
Minimizar Error
(ajuste del modelo)
Maximizar Margen
(generalización)

SVM Lineal – Caso Separable
N objetos que consistenten del par : xi ? Rm, i=1,…,n y de su “etiqueta” asociada yi ? {-1,1}
Supongamos que ? un hyperplano separador w?x+b=0 que separa los ejemplos positivos de los ejemplos negativos. Esto es, Todos los objetos del conjunto de entrenamiento satisfacen:
Sean d+ (d-) las distancias más cercanas desde el hiperplano separador al ejemplo positivo (negativo) más cercano. El margen del hiperplano separador se define como d+ + d-
equivalentemente:

w?x+b=0

SVM Lineal – Caso No-Separable
N objetos que consistenten del par : xi ? Rm, i=1,…,n y de su “etiqueta” asociada yi ? {-1,1}
Se introducen variables de holgura positivas ?i:
Corresponde al caso linealmente separable
Y se modifica la función objetivo a:

Formulación matemática (SVM primal)
Error en
clasificación
1/Margen
W: Normal al hiperplano
separador.
b : Posición del hiperplano
Xi: Objetos de entrenamiento
Yi : Clase del objeto i.
: Error en la separación

Clasificador
El clasificador lineal de los SVM es:
Se determina el signo de la función f(x)
Si signo(f(x)) = +1 pertenece a clase +1
Si signo(f(x)) = -1 pertenece a clase -1

SVM no lineal
Objetos linealmente no separables en R2, pueden serlo otro espacio

SVM no lineal
Idea:
Proyectar los objetos a un espacio de mayor dimensión y realizar una clasificación lineal en este nuevo espacio.
Función de transformación
Basta reemplazar xi· xs por K(xi , xs )

Kernel Machines
(Gp:) Condición de Mercer

Características de Support Vector Machines
Herramienta matemática
No tiene mínimos locales (árboles de decisión)
No tiene el problema de Overfitting (Redes Neuronales)
Solución no depende de estructura del planteamiento del problema.
Aplicabilidad en distintos tipos de problemas (Clasificación, Regresión, descubrimiento de patrones en general)

76
Experiencias acerca de proyectos BI 1/2
Tiempo
proyectos necesitan más tiempo que estimado
Calidad de los datos
muy importante para lograr resultados válidos
Cantidad de datos
en general hay muchos datos disponible pero no siempre para apoyar la toma de decisiones
(base de datos transaccional / bodegas de datos)

77
Experiencias acerca de proyectos BI 2/2
“Mentor” del proyecto
Mentor con alta posición en la jerarquía (proyectos de data mining necesitan apoyo de varios expertos)
Demostración del beneficio
Fácil en el área de ventas / Difícil en segmentación de mercados (por ejemplo)
Mantenimiento del sistema instalado
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |